
When a study session is complete, your results become available for download. In this post, we’ll look at how to access and understand your results files.
Throughout this tutorial, we’ll be referring to study sessions rather than studies. This is because a single study can be launched across multiple simultaneous or sequential sessions. You might want to run multiple sessions simultaneously if you’re using different online recruitment platforms or targeting different participant populations with each session. This would allow you to compare the data from each session and ensure no significant differences across those participants. You can also run multiple sessions of a study sequentially, perhaps using your first session to pilot your study, or using subsequent sessions to test for longitudinal differences. Regardless, remember that each study session will generate separate data files.
Accessing data files
After navigating to your list of studies (by clicking the “Research” tab on the menu bar at the top of the screen and then clicking “Studies”), you’ll see a menu bar on the left side of the screen that allows you to filter your list of study sessions according to completed studies.
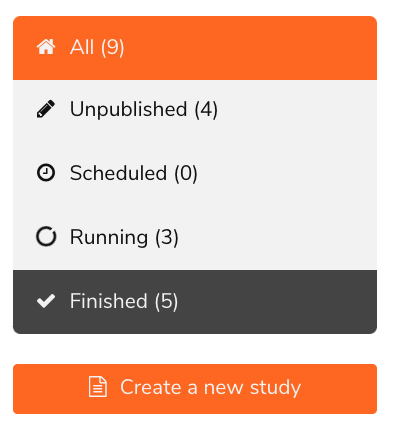
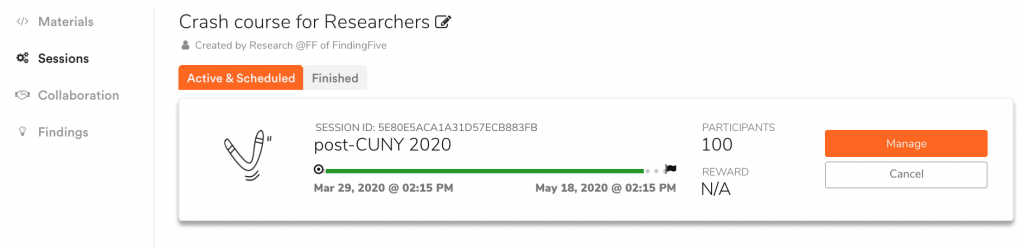
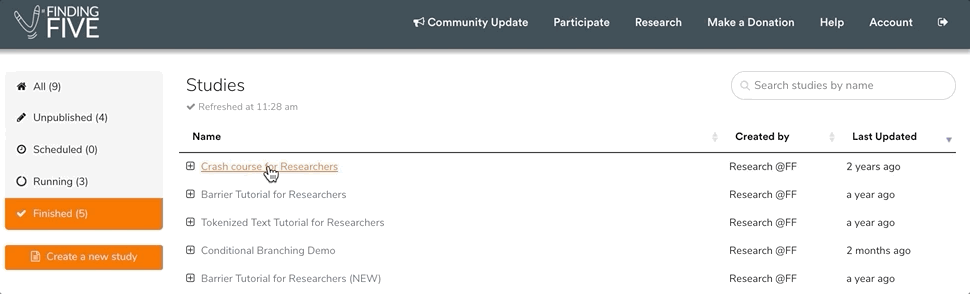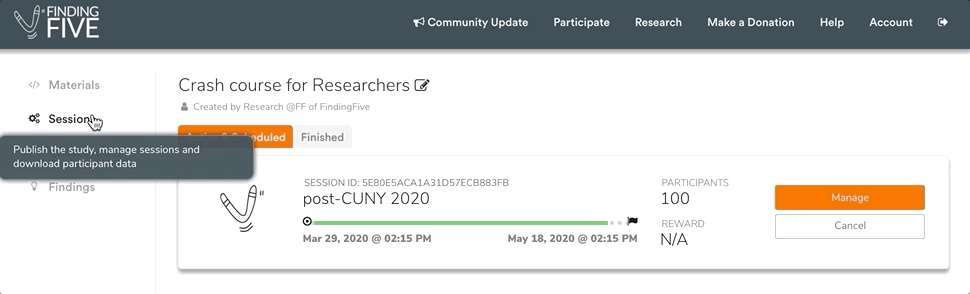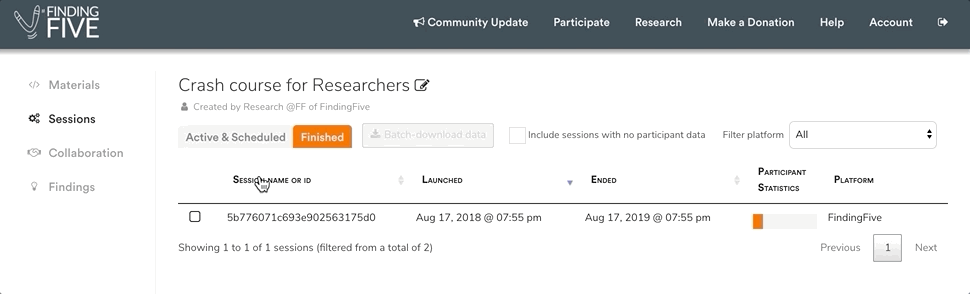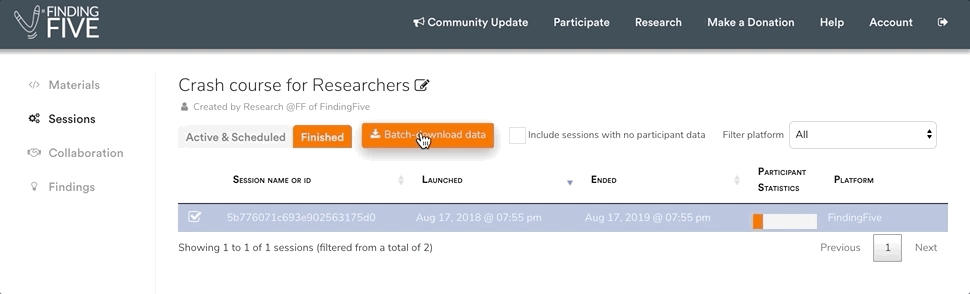
To access a study’s ongoing and completed sessions, first click on the target study’s name in your list of finished studies. This will bring you to the study’s material and code page. Then click on the “Sessions” tab in the left menu bar. Here you can find a list of all ongoing and completed sessions for this particular study. For example, our Crash Course sample study currently has one active session that will close on May 18, 2020:
…and it has one finished session that ended on August 7, 2019:

Each completed study session will include the session name (a handy nickname you set when you launched the session) or session ID (a string set by FindingFive), the session’s starting and ending dates, some insights about completion and abandonment rate, and the platform the study was launched on (FindingFive vs. Mturk).
You can only download results from completed study sessions. If you want to end an active session early, simply click on the large “Manage” button next to the active session. This will bring you to a management page with buttons allowing you to extend (plus button) or end (stop button) this session. Stopping the session will immediately move this study session to the “Finished” sessions tab, and will allow you to access the results files.
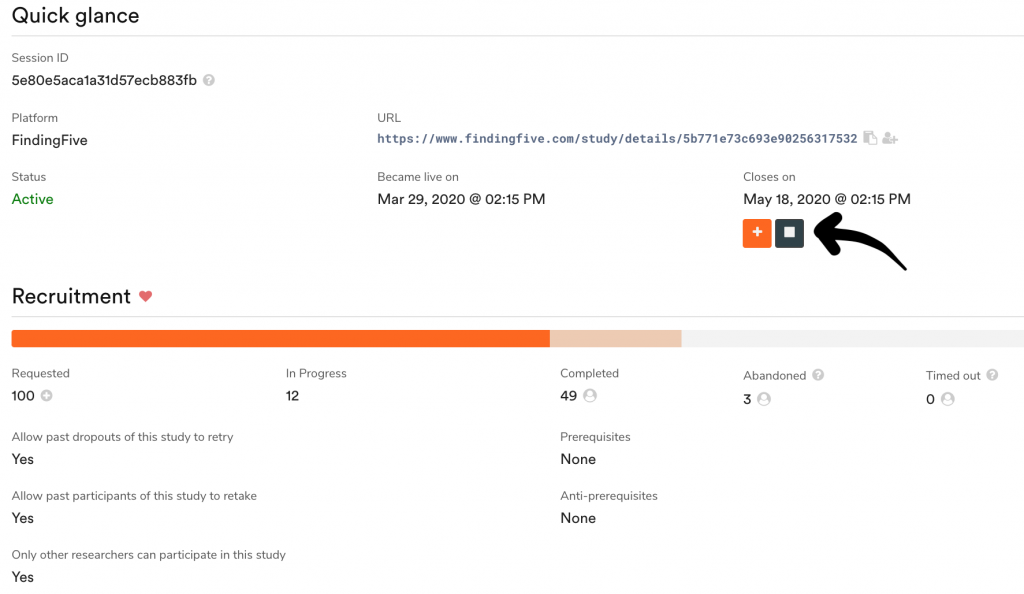
If you stop a session early, you will not be able to restart it! Instead, you’ll have to start a whole new session. (FindingFive does this as a way to encourage best practices and discourage behaviors like p-hacking!)
When you look at your list of finished sessions, you’ll see the option to download some or all of your sessions’ data as zip files. Simply click on the checkbox next to the sessions of interest, and then click on the “Batch-download data” button at the top of the screen.
Exploring data files
Depending on the types of responses you use in your study, your zipped data file may contain only csv (comma separated values) files, or may also include other data file types such as audio files. To learn more about the types of data you can collect in FindingFive, check out the grammar reference page on responses. In this blog post, we’ll focus on exploring the csv data file that is generated by each completed study session.
Each row of your data file corresponds to a participant’s data from one trial of your study. The first 5 columns of your data file will provide basic information about the experiment, the session, and the participant. The first column lists the Experiment ID, which is typically set by FindingFive as a unique random string. If you specified participant groups when setting up your study’s procedure, the group_id column will list the participant’s group. If no participant groups were identified, then the group_id column will say “default” for all participants. You’ll also find the participant’s unique identifier (a unique string generated by FindingFive) and the length of time (in seconds) that the participant took to complete the study.
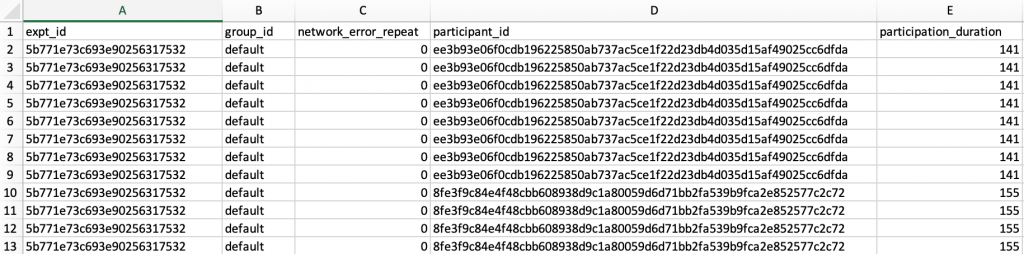
The network_error_repeat column is used to display whether the results on a trial were successfully submitted to the server. You should almost never encounter a number greater than zero in this column. If you see a long list of zeros, that’s perfect! However, in the rare event that you do see a value greater than zero, you might want to proceed with caution when interpreting the results of that trial. It’s possible that there was a network delay causing a participant’s responses to be submitted to the server more than once, or it’s possible that the participant’s internet cut out during this trial.
Subsequent columns display values corresponding to the actions and events occurring in each trial of your study. Below is a snippet of a sample data file from our Crash Course sample study, showing some stimulus and response values:
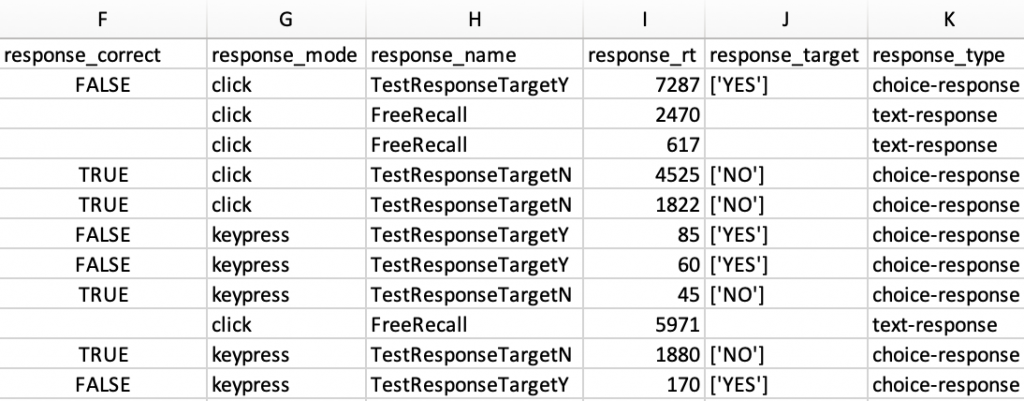
Some of the trials use choice responses, and have correct and incorrect responses. Other trials are text responses, and do not have a corresponding correct answer. The correctness of a response is listed in the response_correct column; subsequent columns show the way the response on a trial was made (e.g., mouse click, keypress, auditory recording), the name you gave this particular response in your code, the participant’s reaction time in seconds from the start of the trial to the submission of a response, the correct target for the trial (if the trial has a correct answer), and the type of response used in this trial (choice, text, audio, etc.).
If you have any questions about this post or the way data is recorded, reported, or stored in FindingFive, please don’t hesitate to contact us at researcher.help@findingfive.com!