
Several months ago, we announced the winners of two FindingFive research awards, generously sponsored by Qntfy! The award recipients have since completed their projects, and we’re excited to share their results.

HyeonAh Kang, PhD Candidate (University of Arizona) investigated the benefits of an output activity (OA)–a task in which language learners read or listen to a text containing target vocabulary words prior to a vocabulary evaluation–in second language (L2) learning. Kang specifically aimed to determine the role of the instructor in positive outcomes from an OA activity: does OA itself positively affect learning of new vocabulary, or does the announcement of OA in the instructions play a role?
Kang found that, when scoring was lenient, a significant linear trend showed participants who were informed that they would encounter an OA involving non-words (Announced) performing better than those who did not receive an announcement (Unannounced), who in turn performed better than control participants (who were forewarned of an OA involving English words, instead of non-words). When scoring was strict, this relationship was non-significant.
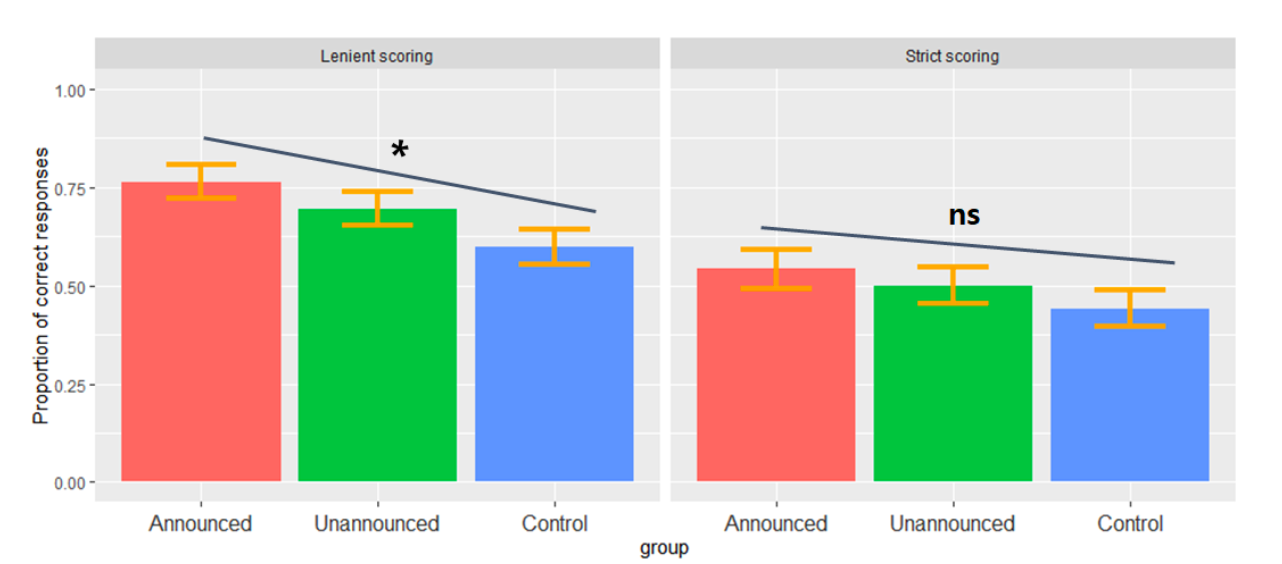
Kang’s findings suggest that the announcement of the forthcoming OA can prime form-meaning mappings within the semantic category of the word.
Methods. All participants used FindingFive to read a passage containing 16 target non-words. They then completed a fill-in-the-blank OA evaluation, in which they used a word bank to complete a summary of the story they had just read. For the Announced and Unannounced groups, the word bank contained target non-words, whereas the control group word bank listed English words. Participants in the Announced and control groups were forewarned of the OA task. All participants then completed an unannounced vocabulary test asking for English translations of each non-word, followed by a True/False comprehension test on 16 summary sentences of the initial passage.
Correct responses on the fill-in-the-blank OA and comprehension test earned one point and incorrect answers earned zero points. The vocabulary test used two scoring methods: under strict scoring, only exact translations of the target word counted as correct; under lenient scoring, responses of the same semantic category as the target word also counted as correct (e.g., ‘shelter’ and ‘building’ for the target ‘glabe’ = ‘house’).
A final sample of 83 English-speaking adults was included in the analyses.
Analyses. Kang used a mixed-effects logistic regression to predict the effect of the OA announcement on learning new vocabulary, with random intercepts for participants and items defined as original words (e.g., ‘house’ for the target nonword ‘glabe’).
Shiloh Drake, PhD & Erin Liffiton, undergraduate (Bucknell University) studied differences in processing speeds of human speech and computer-synthesized speech. Using an auditory masked-priming task–a task in which participants hear a prime hidden in background noise, like speech at a party–Drake and Liffiton assessed whether participants produced different reaction times when primed with a human voice as compared to a synthesized voice.
In a sample of 40 English-speaking adults, when primed and tested with real words (as opposed to nonwords) participants responded more quickly to synthesized speech rather than human speech. For nonwords, there was no difference in response times between the two conditions. The experimenters saw no effect of primes’ word status on reaction times.
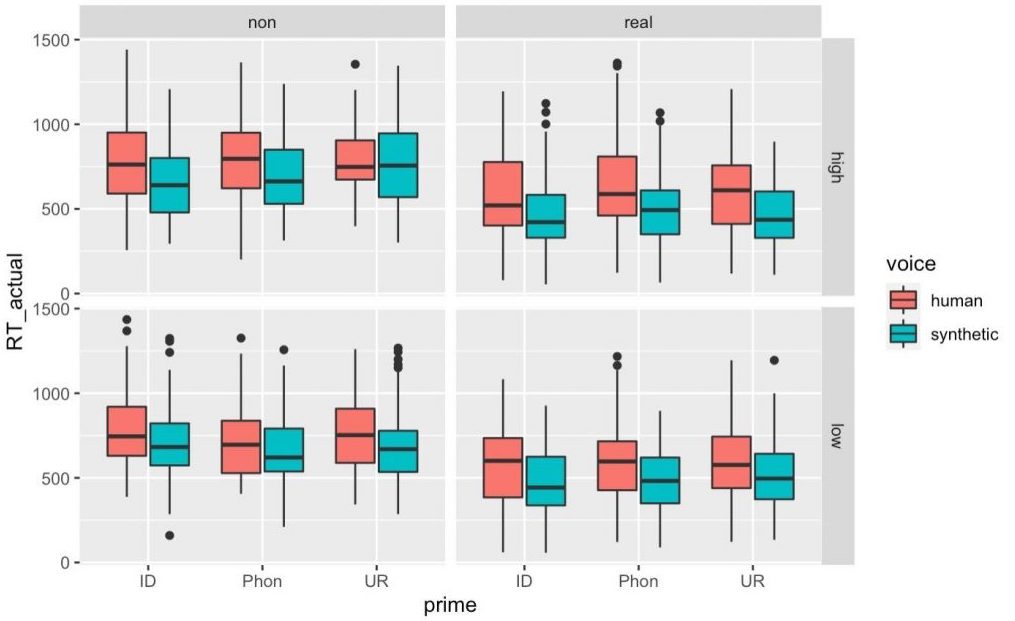
Methods. Drake and Liffiton studied this phenomenon using FindingFive to expose participants to a human-voiced or synthesized prime that contained either an English word or a nonword prime. Following the prime, participants had to determine whether the target word was a real English word or a non-word via key-presses: the Y key indicated “Yes, this is a word of English,” and the N key meant “No, this is not a word of English.” Instructions notified participants that there would be background noise accompanying each item. Participants heard and responded to six practice items before the test, none of which appeared in the experimental block.
Analyses. The authors conducted analyses on a subset of participants’ responses: they pulled only correct responses from congruent trials. So, analyses were conducted on trials in which participants heard a non-word prime and correctly identified the target as a non-word, or when they heard an English word prime and correctly identified the target word as a real English word. Trials in which non-words primed English words and vice versa, or where participants answered incorrectly were not included. The researchers used linear mixed-effects modeling in R with the lme4 package, parceling the individual effects of voice-type (human vs. synthetic), prime-type (identical, phonological, or unrelated), neighborhood density (high vs. low), and word status (word vs. nonword). The model used random slopes and intercepts for each subject and item.
Questions?
Interested in becoming a Premium member or learning more about a Laboratory membership for your research lab or institution? As always, we are happy to help with membership inquiries and other concerns at researcher.help@findingfive.com. For general research-related questions, please check out our forum!