
FindingFive allows you to quickly and easily design experiments for deployment on the web. In this crash course, we will take a detailed tour through some of FindingFive’s features by designing a simple memory study: a modification of Craik and Tulving (1975). We highly recommend you follow through this example carefully before creating your own experiment.
This crash course focuses on building a very simple experiment in order to jumpstart your FindingFive experience. But FindingFive can do so much more! Please be sure to check out the Study Grammar Documentation, which is a reference dictionary for all of the functions of our platform. Also check our our Researcher Tutorials to learn about all of the other features we aren’t covering in this crash course, like conditional branching, or automatically assigning participants to different conditions.
Getting started
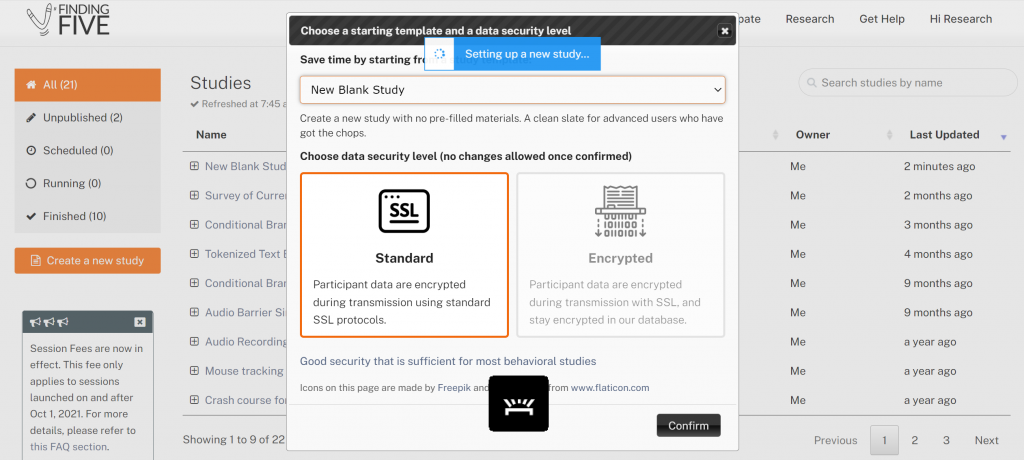
Once logged in, let’s begin by clicking “Research” in the top navigation panel of the screen and selecting “Studies” from the drop-down menu. This allows you to see your list of current and past studies. Clicking the “Create a new study” button on the left side of the screen will result in a pop-up menu in which you can select a starting template and data security level. Leave the defaults in place (“New Blank Study” under templates and “Standard” data security) and click “Confirm”.
This will take you to the study editor page for your new study:
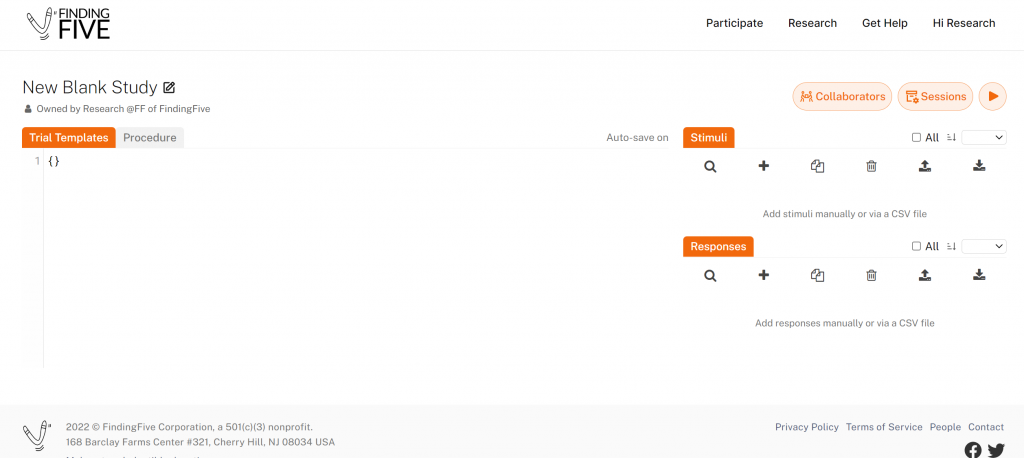
By default, FindingFive creates a study named “New Blank Study” so you can dive straight into editing the study materials. Let’s start by giving our study a new name. This name is how you will find this study later in your list of studies, so choose a name that is meaningful to you. To change the study name, click the editing icon to the right of “New Blank Study”.
Building Your Study
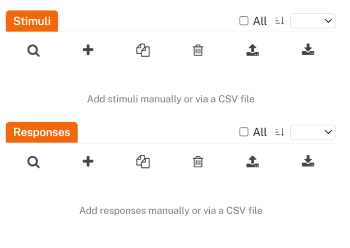
The study editor page is where you will design and build your study. A FindingFive study is created by defining four components that should sound intuitive to those with some training in experimental design: stimuli, responses, trial templates, and procedure. (More details about all of these features can be found in our grammar reference documentation.)
These four components get defined here on your study editor page. On the right-hand side of this page, you can search, add, import, and export the definitions of stimuli and responses. These make up the basic building blocks of any study.
On the left-hand side of the screen, you can use the code editor to create trial templates, which combine stimuli and responses to form trials, and the procedure, which defines how trials are organized in a study. These are the two components that involve some coding (but rest assured that we will walk you through it!).
Coding Basics
FindingFive uses a JavaScript Object Notation (JSON) based coding interface, so familiarity with basic JSON syntax rules will be helpful in building your first FindingFive study. To learn more about these rules and the data structures supported by JSON, check out this resource.
Translating Craik and Tulving (1975) to the FindingFive Study Specification
Our version of Craik and Tulving (1975) in plain words
In our sample experiment, participants will be presented with word pairs (training), then asked to recognize and recall the word lists after a delay (testing). Some pairs of words will be semantically congruous, while others will be semantically incongruous. We expect that semantically congruous word pairs are recognized and recalled more quickly and accurately than semantically incongruous word pairs during the testing phase of the experiment.
Translating Craik and Tulving (1975) using the FindingFive Study Specification
This study procedure will be implemented in two blocks: a training block, and a testing block. Trials in the training block will consist of presenting words and instructions, which are all stimuli that we will organize within trial_templates. Trials in the testing block will present words and instructions as well, but will also contain two types of responses. In the first response type, participants will be asked if the presented pair of words is correct (a two-alternative forced choice recognition memory test). The other response type will require participants to recall the target word and type it into a text box. These two kinds of test trials will each be organized into their own trial_template.
To build the study specification for our study, we must therefore:
- Define
stimuliwhich will include our training and test instructions to the participant, the word-pairs that the participant must learn during our training phase, and the test questions we will ask the participant to respond to - Define
responsesfor the test phase of the experiment, both 2AFC and free recall - Define
trial_templatesfor each set of trials in our study (instruction trials, training trials, 2AFC test trials, and free recall test trials) - Define the
procedure, which will consist of a training block and then a testing block
Setting up the stimuli
We’ll build our experiment from the ground up, starting with the stimuli. Stimuli are items that are presented to the participant, including text instructions, audio clips, images, and videos. For our experiment, we will need to define stimuli for our training and test instructions, each of our word-pairs and test questions, and a concluding statement to the participant at the end of the study.
Add the first two stimuli manually
To create our training instructions, let’s define a new stimulus. To add a new stimulus to our study, click on the + button under the Stimuli menu in the left sidebar. A new window will pop up, asking for the name of the stimulus, and the definition of the stimulus:
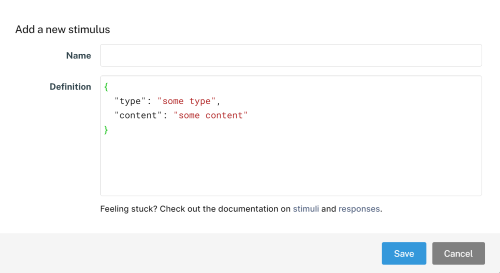
Let’s name this stimulus TrainingInst. This stimulus will only contain text, so we will set the type property to “text”. We will define the content property with our experiment instructions. We’ll also define an optional property called alignment, which we will set to “center.” (This ensures the content is center-aligned on the screen.) Type “TrainingInst” into the name field, paste the following code into the definition field, and click Save:
{
"type": "text",
"content": "In this first part of the experiment, you will see pairs of words presented on the screen. Your task is to <b>remember the capitalized words in each pair</b>. However, you should pay attention to both words and notice the relationship between them, since this relationship will help you remember the capitalized words.",
"alignment": "center"
}Notice that we can use HTML tags (like <b> for bold font) to alter the appearance of our text stimulus. We can also add comments to ourselves that FindingFive will ignore; you can add comments after a double-forward-slash (“//”). Lines of code in a block are separated by commas, while the last line of code before a closing curly brace (“}”) has no comma. As an exercise, add a second stimulus named “TestInst”, which has the following definition:
{
"type": "text",
"content": "In this portion of the study, you will be prompted with one of the two words in each word pair you learned. Your job is to indicate the correct match to the presented word. In some test trials, you will type the word into a text box. In others, you will indicate whether the presented match is correct.",
"alignment": "center"
}Congratulations! You have successfully added the first two stimuli of your study. They should now be displayed in the Stimuli sidebar.
Add more stimuli via CSV batch uploading
Next, we’ll create stimulus definitions for each of the words to be presented in the training phase of the experiment. Doing so individually can be quite tedious. Fortunately, FindingFive supports batch uploading of stimuli via a CSV file, which makes life much easier when we are dealing with potentially hundreds of stimuli.
To get started, hover your mouse over the batch upload button under Stimuli, and a brief explanation on how to format stimulus definitions in the CSV will pop up:
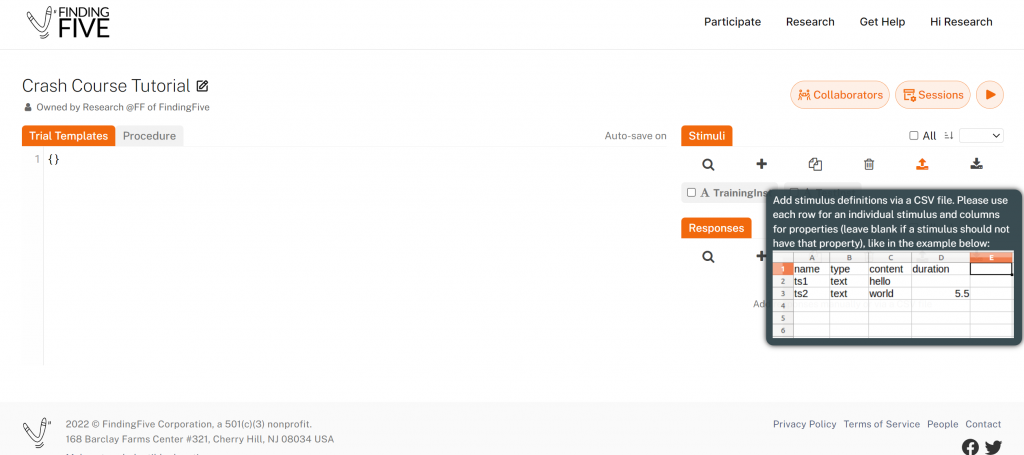
For our current example, Craik and Tulving (1975), use your favorite spreadsheet software (Excel, Google Sheets, or other great programs) to create a CSV file that looks like this:
| name | type | content | alignment |
|---|---|---|---|
| ConCue1 | text | player | center |
| ConTarget1 | text | BALL | center |
| ConCue2 | text | smooth | center |
| ConTarget2 | text | HARD | center |
| ConCue3 | text | furniture | center |
| ConTarget3 | text | CHAIR | center |
| ConCue4 | text | fire | center |
| ConTarget4 | text | COLD | center |
| InconCue1 | text | fruit | center |
| InconTarget1 | text | FLOWER | center |
| InconCue2 | text | moth | center |
| InconTarget2 | text | FOOD | center |
| InconCue3 | text | cheese | center |
| InconTarget3 | text | GREEN | center |
| InconCue4 | text | cave | center |
| InconTarget4 | text | WET | center |
| ConTest1y | text | Was <b>ball</b> the word paired with <b>player</b>? | center |
| ConTest1n | text | Was <b>tennis</b> the word paired with <b>player</b>? | center |
| ConTest2y | text | Was <b>hard</b> the word paired with <b>smooth</b>? | center |
| ConTest2n | text | Was <b>soft</b> the word paired with <b>smooth</b>? | center |
| InconTest1y | text | Was <b>flower</b> the word paired with <b>fruit</b>? | center |
| InconTest1n | text | Was <b>bloom</b> the word paired with <b>fruit</b>? | center |
| InconTest2y | text | Was <b>food</b> the word paired with <b>moth</b>? | center |
| InconTest2n | text | Was <b>eat</b> the word paired with <b>moth</b>? | center |
| ConTest3 | text | What was the word paired with <b>furniture</b>? | center |
| ConTest4 | text | What was the word paired with <b>fire</b>? | center |
| InconTest3 | text | What was the word paired with <b>cheese</b>? | center |
| InconTest4 | text | What was the word paired with <b>cave</b>? | center |
| BreakInst | text | Please take a short break | center |
You’ll notice in our CSV that the first 16 rows are the training stimuli, followed by the stimuli to display for the test trials. For the test trials, the word stimuli may seem somewhat a misnomer – these are used to display the questions participants will answer. The last stimulus will be used to prompt the participant to take a break before the test portion of the experiment. (Note that if you had wanted to batch upload the original training and test instructions, you could have added them into the CSV file as two additional rows.) We recommend carefully considering the names of your stimuli and responses so that they are easy to organize in your stimuli and responses lists. This will also help with data analysis when it’s time to download and analyze your findings, since the stimulus and response names will be listed in your data files.
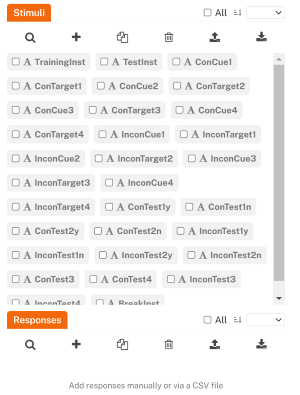
Let’s upload this CSV and create those stimuli all at once!
Click the batch upload button, and select the CSV file on your computer. For this particular example, these stimuli should be imported in just a second. However, when uploading hundreds of stimuli at once, this process might take up to a couple of minutes, depending on the speed of your computer and the Internet connection.
Please be patient and do not refresh the page unless you are absolutely sure something unexpected has happened. After the upload is complete, you should see the Stimuli sidebar populated with your stimuli!
Note:
Although we’re only dealing with static text stimuli in this crash course, you could have batch uploaded a CSV file describing other types of stimuli using the same method. The columns of your CSV file list the properties of your stimuli, while the rows of your CSV file define the individual stimuli that you’ll use in your study.
Setting up the responses
Responses define the actions that participants can take in response to stimuli. They also automatically specify what types of participant data will be recorded. In our sample experiment, we will conduct both a recognition (2AFC) memory test and a recall (fill-in-the-blank) memory test. We will set up the actions participants can take for these test trials by defining responses.
Let’s start by creating responses for the recognition test for our semantically congruous and incongruous word pairs. Adding a response to a study is very similar to adding a stimulus. Click the + button under Responses, and you will be prompted to name and define the new response:
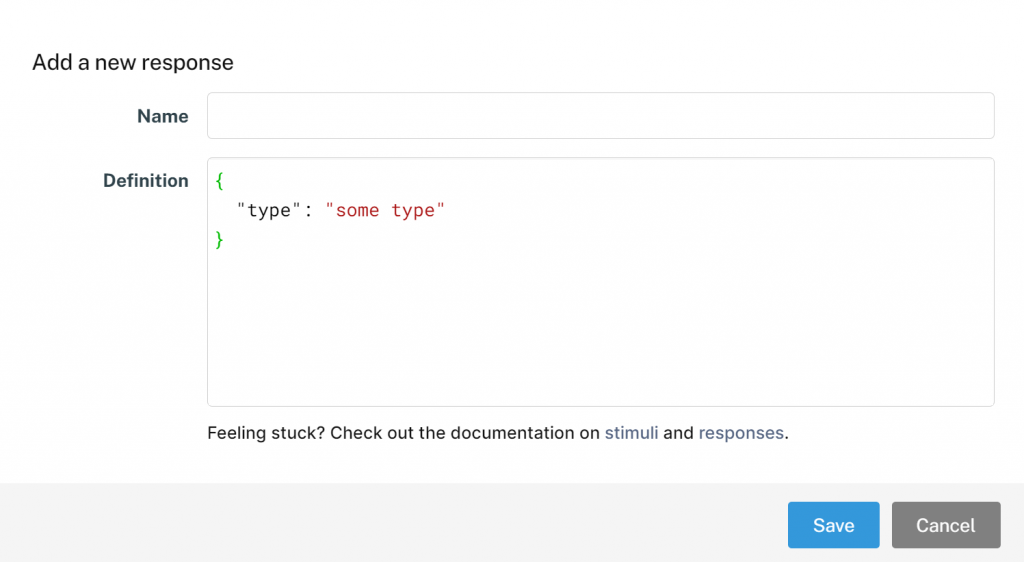
Since we are asking participants to make a choice between two options (correct pairing, or incorrect pairing), the type of response we will collect is a “choice” response. We can define the possible choices for the participant (in this case, YES or NO) using the choices property. Next, we will map these choices to keys on the participant’s keyboard using the key_mapping property and we will tell FindingFive which choice is correct using the target property. Since the correct answer can either be YES or NO, we’ll make two responses, one for each of these possibilities.
The first response is named “TestResponseTargetY”, with the definition:
{
"type": "choice",
"choices": ["YES", "NO"],
"key_mapping": ["F", "J"],
"target": "YES"
}The second response is named “TestResponseTargetN”, with the definition:
{
"type": "choice",
"choices": ["YES", "NO"],
"key_mapping": ["F", "J"],
"target": "NO"
}Next, we will set up our recall test. The type of response we will collect is a “text” response, so there’s no need to define choices or key_mapping, but we can set a character limit for participant’s responses using max_char. We will name the response “FreeRecall”, and use the following definition:
{
"type": "text",
"max_char": 10
}And that’s it – we are all set with the responses! At this point, your right sidebar should look something likes this:
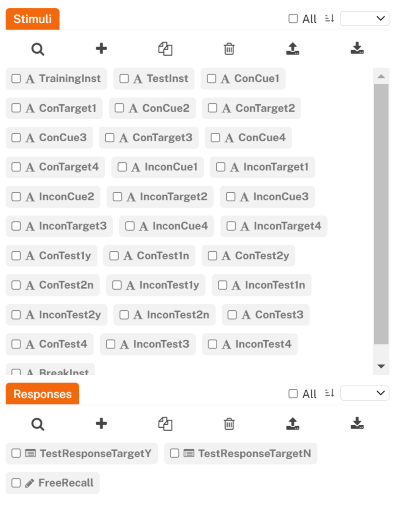
Note:
As with stimuli, there are many more types of responses in FindingFive than what we are using in this crash course.
Setting up the trial templates
Now that we have the stimuli and responses defined, we can set up the trial_templates that define the organizational logic of our trials. We will define trial_templates for each set of trials in our study (instruction trials, randomized training trials, randomized 2AFC test trials, and randomized free recall test trials).
Trial templates are defined in “Trial Templates” tab of the code editor. Please make sure that tab is selected (the selected tab is orange). Notice that the code editor starts with a pair of curly braces. All trial templates will be defined inside these curly braces.
Instruction trials
First, let’s set up our instruction trials. The following code segments will be inserted inside the curly braces on the initial code editor screen. We’ll skip showing you these outermost curly braces until the end of this section, when we’re done putting all of our code segments together.
First we’ll need an instruction trial (“T1”) at the very beginning of the experiment to explain the training trials to our participants. Defining the type as “instruction” allows us to simply present text to the participant for a time in seconds specified by duration. Participants must wait until the specified duration has elapsed before continuing the experiment (by clicking a button labeled “continue” that appears after the specified duration). This “T1” instruction trial template should look like this:
"T1": {
"type": "instruction",
"stimuli": ["TrainingInst"],
"duration": 10
}, // you should keep the comma here if more trial template definitions follow this one
Notice that we have put the full trial template definition inside of the curly braces. The indentation you see in this example is for readability only – white space does not affect the results of the code. In subsequent code samples we will not show the outer curly braces or indent the code for you. We encourage you to adjust the indentation in whatever way is clearest for you!
Now let’s define similar trial types for presenting the break instructions, test instructions, and a final goodbye message to the participants.
"PreTestBreak": {
"type": "instruction",
"stimuli": ["BreakInst"],
"duration": 30
}, // you should keep the comma here if more trial template definitions follow this one
"T2": {
"type": "instruction",
"stimuli": ["TestInst"],
"duration": 10
}, // you should keep the comma here if more trial template definitions follow this oneYou can copy and paste the code above into the code editor – please make sure that the “Trial Templates” tab is selected before doing so, and that each trial template definition is placed inside the outer set of curly braces as described above.
Training Trials
For the training trials, we create a template named “TrainingTrials”. Since we need to present 8 word-pair stimuli in total, the trial template is set up to generate 8 unique trials, each of which presents two stimuli. Note: to include two stimuli on each trial we create a list for each of our trials within the larger stimuli list.
"TrainingTrials": {
"type": "basic",
"stimuli": [["ConCue1","ConTarget1"],["ConTarget2", "ConCue2"],["ConCue3", "ConTarget3"], ["ConTarget4", "ConCue4"], ["InconCue1","InconTarget1"],["InconTarget2", "InconCue2"],["InconCue3","InconTarget3"], ["InconTarget4", "InconCue4"]],
"stimulus_pattern": {"order": "random"},
"duration": 3,
"delay":1,
"responses": []
}, // you should keep the comma here if more trial template definitions follow this oneHere, a simple per-participant randomization of the 8 trials is achieved by specifying the stimulus_pattern property. As in Craik and Tulving (1975), these stimuli will remain on the screen for 3 seconds each, achieved by the duration property. The delay property handles time between trials – here we set it to 1 to indicate a 1-second inter-trial-interval. We won’t collect any data from the participant in these training trials, so our responses property is set to an empty list [].
Test trials
Last, we create the trial templates for test trials. First, let’s handle the 2AFC test trials by making a trial template for trials where the correct response is YES and a second trial template for trials where the correct response is NO. FindingFive has a built-in trial template for alternative forced choice tasks (“AFC”), so we’ll use that here. Like the training trials, the test will present our test trials in a random order.
"TestTrials2AltY": {
"type": "AFC",
"stimuli": ["ConTest1y", "ConTest2y", "InconTest1y","InconTest2y"],
"stimulus_pattern": {"order": "random"},
"responses": ["TestResponseTargetY"]
}, // you should keep the comma here if more trial template definitions follow this one
"TestTrials2AltN": {
"type": "AFC",
"stimuli": ["ConTest1n", "ConTest2n", "InconTest1n","InconTest2n"],
"stimulus_pattern": {"order": "random"},
"responses": ["TestResponseTargetN"]
}, // you should keep the comma here if more trial template definitions follow this oneWith our 2AFC test trials set, we just need to define the trial template for the free recall test trials.
"TestTrialsFree": {
"type": "basic",
"stimuli": ["ConTest3", "ConTest4", "InconTest3","InconTest4"],
"stimulus_pattern": {"order": "random"},
"responses": ["FreeRecall"]
} // this will be the last trial template definition, so there is no commaAt this point, your full trial templates code should look like this (assuming you indented your trial templates like we did!):
{ // this is the outermost curly brace from the original code editor screen
"T1": {
"type": "instruction",
"stimuli": ["TrainingInst"],
"duration": 10
},
"PreTestBreak": {
"type": "instruction",
"stimuli": ["BreakInst"],
"duration": 30
},
"T2": {
"type": "instruction",
"stimuli": ["TestInst"],
"duration": 10
},
"TrainingTrials": {
"type": "basic",
"stimuli": [["ConCue1","ConTarget1"],["ConTarget2", "ConCue2"],["ConCue3", "ConTarget3"], ["ConTarget4", "ConCue4"], ["InconCue1","InconTarget1"],["InconTarget2", "InconCue2"],["InconCue3","InconTarget3"], ["InconTarget4", "InconCue4"]],
"stimulus_pattern": {"order": "random"},
"duration": 3,
"delay":1,
"responses": []
},
"TestTrials2AltY": {
"type": "AFC",
"stimuli": ["ConTest1y", "ConTest2y", "InconTest1y","InconTest2y"],
"stimulus_pattern": {"order": "random"},
"responses": ["TestResponseTargetY"]
},
"TestTrials2AltN": {
"type": "AFC",
"stimuli": ["ConTest1n", "ConTest2n", "InconTest1n","InconTest2n"],
"stimulus_pattern": {"order": "random"},
"responses": ["TestResponseTargetN"]
},
"TestTrialsFree": {
"type": "basic",
"stimuli": ["ConTest3", "ConTest4", "InconTest3","InconTest4"],
"stimulus_pattern": {"order": "random"},
"responses": ["FreeRecall"]
} // this will be the last trial template definition, so there is no comma
} // this is the outermost curly brace from the original code editor screenNote:
There are many more things you can do with trial_templates in FindingFive!
Setting up the procedure
Now it’s time to put everything together into our procedure. We will define the procedure to have two blocks: a training block and a testing block. First things first, let’s switch the code editor to work on the procedure by clicking on the “Procedure” tab:

To begin, every procedure of a FindingFive study requires a type. By default, the type property is set to a “blocking” procedure, where trials are grouped into blocks that are put in a particular order. Blocking procedures also require a definition of blocks, and a block_sequence indicating how those blocks should be ordered:
{
"type": "blocking",
"blocks": {
//your block definitions will go here
},
"block_sequence": [
//the order of block presentation will go here
]
}The training block
Let’s begin creating our training block, which we will call TrainingBlock. To create this block, we will edit the blocks definition of our procedure.
{
"type": "blocking",
"blocks": {
"TrainingBlock": {
// the definition of the TrainingBlock will go here
}
},
"block_sequence": [
//the order of block presentation will go here
]
}A common block definition will include the following properties: the trial_templates that make up the main trials of the block, the pattern that should be used to order those trials within the block, the cover_trials that should precede the main trials of the block, and the end_trials that should follow the main trials of the block.
In this block, we will start by presenting our training instructions, housed in template T1. To make sure these instructions come at the very beginning of the block, we add the T1 template to the block’s cover_trials. We will then present the training trials themselves, housed in template TrainingTrials. Since these are the main trials of the block, we will add the TrainingTrials template to the block’s trial_templates. We will then end the training block with our break instructions, housed in template PreTestBreak. To make sure these instructions come at the very end of the block, we add the PreTestBreak template to the block’s end_trials. Finally, since we’re only presenting one main trial template in this block, and we are presenting it only once, we don’t need to adjust the pattern for this block.
"blocks": {
"TrainingBlock": {
"trial_templates": ["TrainingTrials"],
"cover_trials": ["T1"],
"end_trials": ["PreTestBreak"]
},// you should keep the comma here if more block definitions follow this one
}The testing block
Our test block will look similar to our training block, except that instead of one trial template housing all of our main trials, we have 3 different trial templates for which we want to randomize their trials together: TestTrials2AltY, TestTrials2AltN, and TestTrialsFree. We also want this block to end with the last of our main trials, so we will not define any end_trials for the test block. You may copy and past the TestingBlock definition below into your procedure’s blocks definition:
"TestingBlock": {
"trial_templates": ["TestTrials2AltY", "TestTrials2AltN", "TestTrialsFree"],
"pattern": {"order": "randomized_trials", "repeat": 1},
"cover_trials": ["T2"]
}The block_sequence
Finally, we need to specify the order in which we want these blocks presented to participants. This is done by putting the names of our blocks into the block_sequence property of the procedure in the order that we want them to occur:
"block_sequence": ["TrainingBlock","TestingBlock"]
Note that the block sequence definition uses square brackets, not curly braces! Your final procedure should look like this:
{
"type": "blocking",
"blocks": {
"TrainingBlock": {
"trial_templates": ["TrainingTrials"],
"cover_trials": ["T1"],
"end_trials": ["PreTestBreak"]
},
"TestingBlock": {
"trial_templates": ["TestTrials2AltY", "TestTrials2AltN", "TestTrialsFree"],
"pattern": {"order": "randomized_trials", "repeat": 1},
"cover_trials": ["T2"]
}
},
"block_sequence": ["TrainingBlock","TestingBlock"]
}Note:
FindingFive allows you to create a variety of experimental designs in the procedure.
Making your study ready to run
When you are working on the materials of a study, in the upper-right corner of the web page you’ll notice an orange button ![]() that says “preview study”. This button is how you will verify that your experiment runs as you expect it to.
that says “preview study”. This button is how you will verify that your experiment runs as you expect it to.
Encountering syntax errors in the study specification
As you type in the code editor, some basic syntax errors, such as missing commas, mismatched parentheses, and unrecognized characters, will be checked in real time. If an error is found, you won’t be able to click the preview button: this means that there are syntactic errors in your trial templates and/or procedure. If this happens, you can hover your mouse over the preview button to get a message about the error, as shown below.
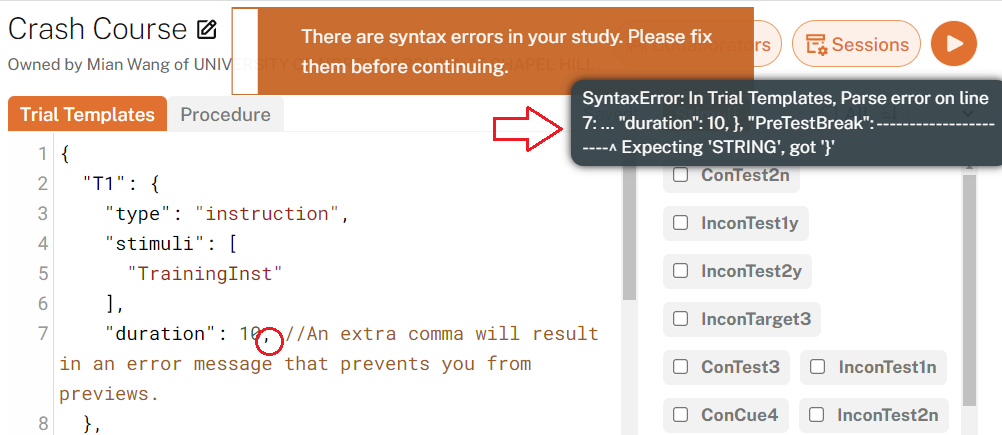
Missing commas between items in a list [] or a dictionary {}
An extra comma at the end of a list [] or a dictionary {}
Use of single quotation marks '' instead of double quotation marks ""
Missing quotation marks "" where they are required
Mismatched quotation marks "", list brackets [], or dictionary braces {} (e.g., quotes open without a corresponding closing quote)
Note:
Having trouble figuring out where your code went wrong? Try using a JSON validator to help you. Free JSON validators can be found on the web – use your favorite search engine to help you find one! Just make sure to remove any comments (beginning with /) before using the validator.
These basic errors must be fixed before more complex errors, which often involve the logic of a study, are detected. These additional problems are investigated after you click on the “preview study” button ![]() , as they are checked by the more powerful study parser on our server. These more complex errors, if found, are reported to you in a language as plain as possible:
, as they are checked by the more powerful study parser on our server. These more complex errors, if found, are reported to you in a language as plain as possible:
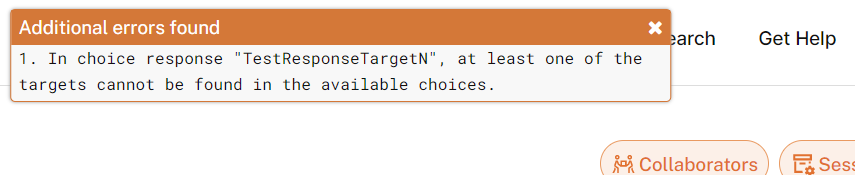
If no additional errors are found, you will be taken to preview the study directly.
Upload necessary resource files for stimuli
If a corresponding resource file is missing, the affected stimulus will be highlighted in red, and you will receive a prompt when your mouse hovers over the stimulus (you may need to refresh your browser to see this prompt). To upload a single stimulus file, simply click on the stimulus and then the “upload file” button.
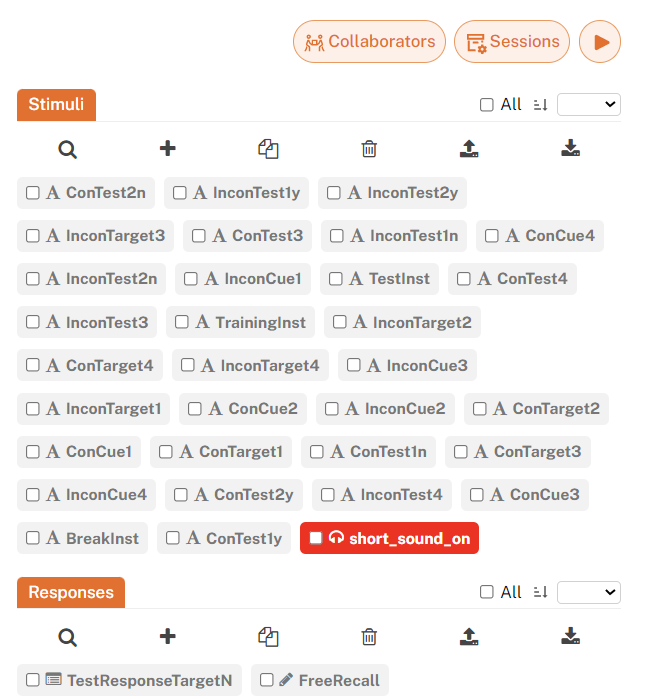
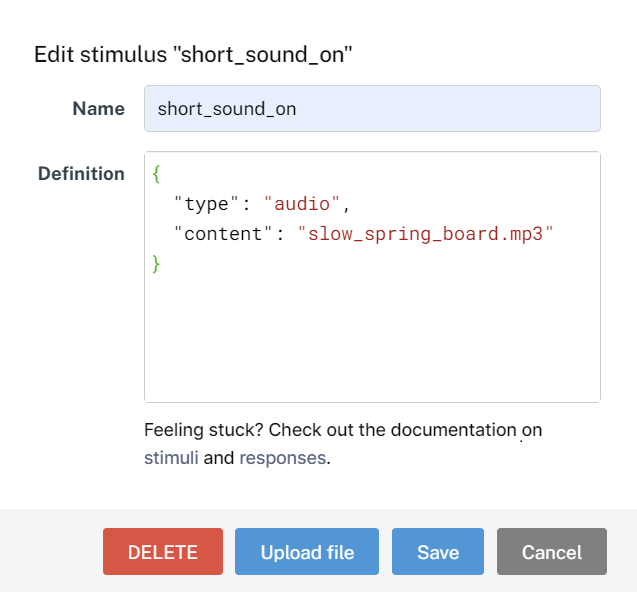
In many cases, a researcher may create different studies that are minor variations of each other. It would be a mind-numbing process to upload the same stimulus files over and over again. Fortunately, stimulus files that are uploaded to one study can be directly accessed by filename in another study within the same account. That is, two file-based stimuli sharing the same “content” property actually point to the same stimulus file uploaded to your account. This is because resource files (including stimulus files and consent forms) are uploaded to a single account-specific resource file folder shared across all of your studies. To see what stimuli are uploaded to your account, you can click on the Research menu at the top right of your screen, then click on Files:
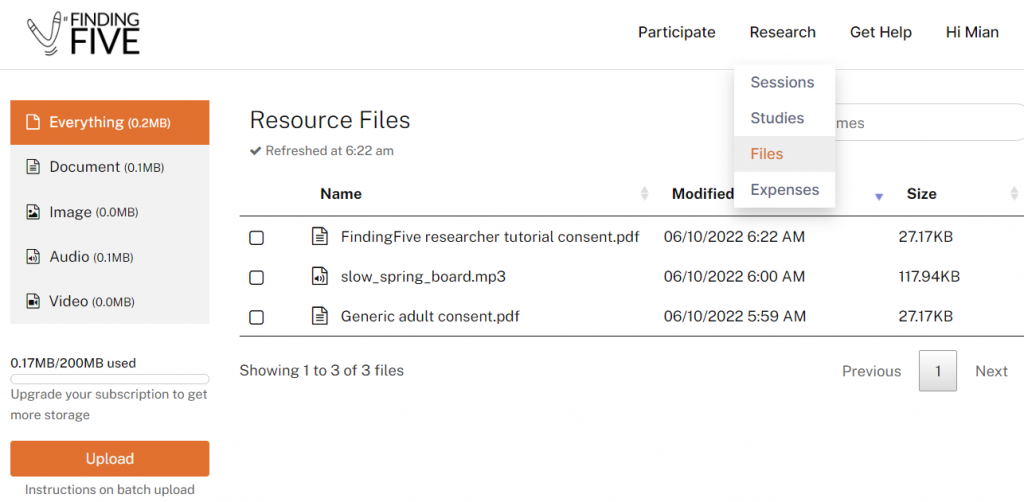
This will take you to a list of all of the resource files that have been uploaded to your FindingFive account, including consent forms, images, videos, and audio files. For example, if we look at the documents that we have saved in our account, we see two consent forms have been uploaded and are available to use across any of our studies: one consent form that is specifically for study tutorials that we create, and another generic consent form that covers most of our other adult studies.
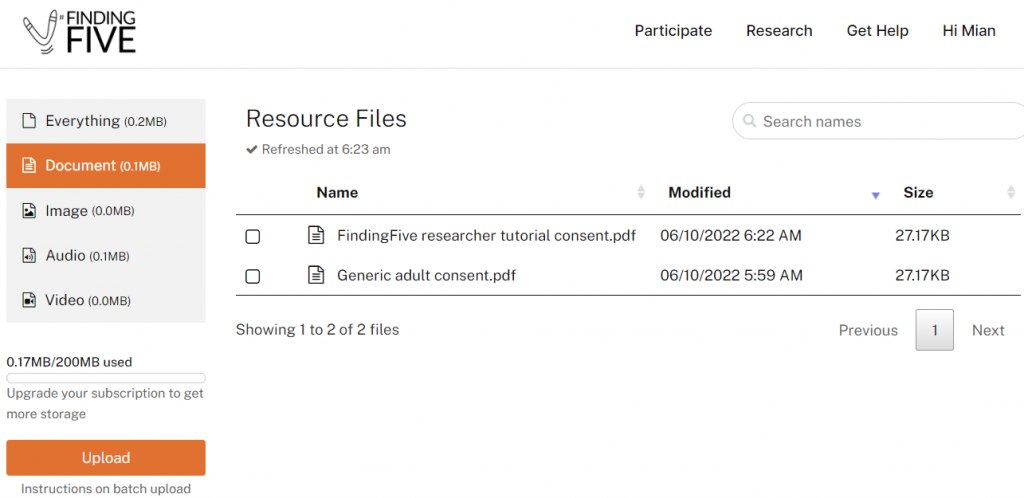
Note:
If you’re a collaborator on a study, but not the creator/owner of that study, you won’t be able to see the resource files associated with that study. Those files are associated with the account that created the study.
Have lots of stimuli to upload? No problem! FindingFive allows for batch uploading of multiple stimulus files and/or consent forms. To do this, gather the desired files into a folder and compress the folder into a ZIP archive. Then, click the “Upload” button on your “Resource Files” page, and select the option to upload a ZIP archive. Please be patient and do not navigate away from the Resource Files screen while the archive is being uploaded.
Your study is now ready to recruit participants and run!
You are now done building your study, and you’re ready to take plunge and run it! Check out our Launching and Managing Sessions tutorial to learn more about deploying your study.
Don’t forget that you can learn much more about the FindingFive platform by looking at the Study Grammar documentation. You can also see other examples of how to customize your studies by looking at the various tutorials we post on our blog!
Have questions about this tutorial? You can always reach out to our researcher help team at researcher.help@findingfive.com.